剑桥大学新研究利用机器学习极大加速帕金森病治疗药物的开发

在剑桥大学研究人员最近发表在《自然化学生物学》期刊上的一项开创性研究中,机器学习的新应用大大加快了对帕金森病的治疗的探索,帕金森病是一种影响全球数百万人的衰弱性神经退行性疾病。这项研究利用先进的计算技术来识别蛋白质α-synuclein的抑制剂,标志着在抗击这种目前无法治愈的疾病方面向前迈出了有希望的一步。
帕金森病的挑战

帕金森病的特点是α-突触核蛋白(α-synuclein)在大脑中的积累和结块。这种现象被认为在该疾病的进展中起着关键作用,导致神经细胞死亡和出现严重的运动和非运动症状。从历史上看,针对这些蛋白质聚集体的治疗的开发一直很缓慢,充满了挑战,主要是由于该疾病的复杂性和传统药物发现方法的局限性,这些方法成本昂贵、耗时,而且往往无效。
机器学习的新颖方法
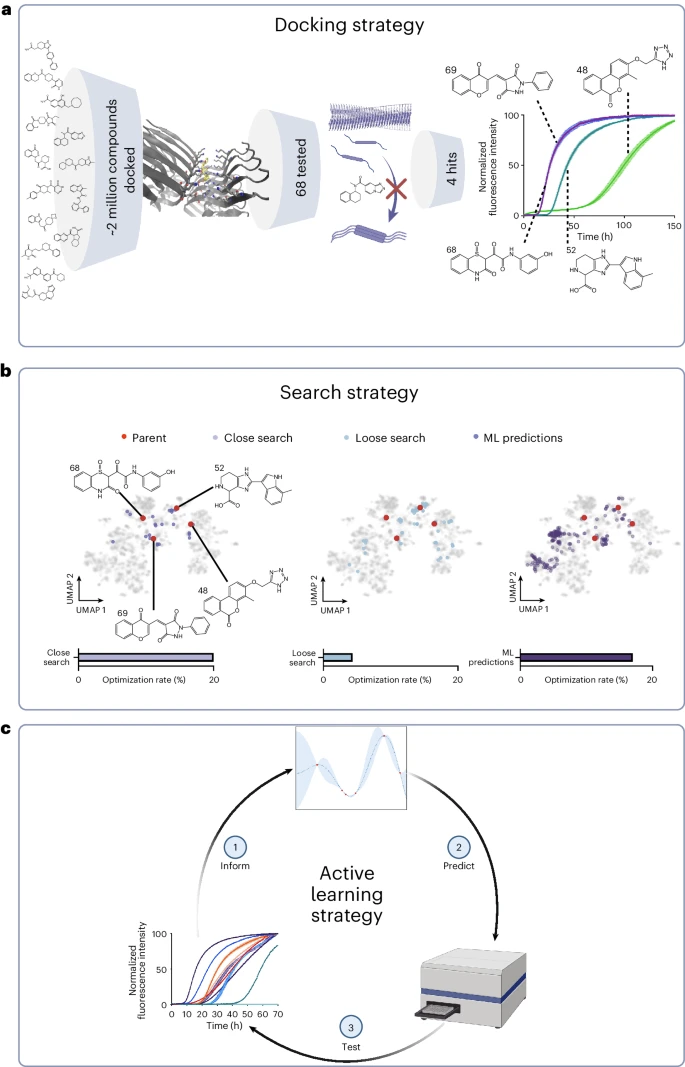
剑桥团队的方法与传统方法有很大不同。通过采用基于结构的机器学习策略(structure-based machine learning strategy),研究人员设法简化了潜在治疗的初始筛选过程,减少了与这些早期阶段相关的时间和成本。研究人员解释说:“我们不是通过实验筛选,而是通过计算来筛选。这种 转变不仅加快了这个过程,而且增强了我们预测化合物在抑制α-突触核蛋白聚集方面的有效性的能力。”
该团队使用机器学习算法快速扫描包含数百万种化合物的化学库。这种快速筛查确定了潜在的抑制剂,然后在实验室合成和测试,这与手动测试每种化合物的传统方法相去甚远。结果令人震惊——人工智能确定了五种高效化合物以供进一步研究,每种化合物都能够阻止α-突触核蛋白的致病聚集。
该研究报告了几个关键发现:

- 高效力化合物:已鉴定的化合物比之前已知的化合物效力高数百倍。
- 成本和时间效率:机器学习方法将筛选成本降低了一千倍,并将过程提高了十倍。
- 迭代优化:通过迭代测试和优化,实验结果不断反馈到机器学习模型中,预测的准确性和有效性显著提高。
这个迭代过程不仅完善了化合物的选择,还增强了机器学习模型预测新潜在抑制剂的能力,为未来神经退行性疾病的药物发现努力设定了基准。
这项研究的与众不同之处在于其有针对性的方法和尖端技术的使用。通过特别关注对次生成核(secondary nucleation)的抑制,因为次生成核是α-突触核蛋白聚集的关键阶段,该研究解决了该疾病病理学的一个关键方面,而许多其他治疗没有这样的特点。此外,机器学习的集成允许在制药研究中达到以前无法达到的精度和效率水平。
对神经退行性疾病的更广泛影响
这项研究的影响超出了帕金森病的范围。开发的方法可能适用于其他神经退行性疾病,如阿尔茨海默病,其中蛋白质聚集也起着至关重要的作用。这可以为药物发现的新时代铺平道路,机器学习可以显著缩短新疗法的开发时间,使他们能够更快地到达患者手中。
此外,这种方法的成功可以鼓励更多的制药研究企业采用机器学习技术,预祝整个行业向更具成本效益和效率的药物发现过程转变。

由于帕金森病仍然是全球增长最快的神经系统疾病之一,迫切需要治疗和药物发现方面的创新。剑桥大学的最新研究不仅证明了机器学习在革命性药物发现方面的潜力,而且也为有效治疗帕金森病和类似疾病的道路可能比之前想象的要短提供了希望。对于数百万患者及其家人来说,这可能意味着朝着更好地管理这些条件和提高生活质量的重大转变。
